You finally arrive home. It’s been a long day of studying mathematics and programming various econometric models at Zernike. To relax, you sit down and open your Spotify app to listen to some music. Usually, you have the same 3 songs on repeat, but you’re feeling a bit adventurous today and decide to toggle on smart shuffle. It’s a song you’ve never heard before, but within seconds, your head is nodding. You didn’t choose this song; a machine chose it for you. Every skip, every repeat, every action is feeding a reinforcement learning system modeled after a classic casino dilemma: The Multi-Armed bandit problem. To maximize your listening time, Spotify must constantly balance "exploiting" what it already knows you love with "exploring" risky, unknown wildcards. Here is the mathematical blueprint of how Spotify gambles with your ears.
To understand how Spotify guides your taste, we first have to go back to a classic problem in probability theory and machine learning: The so-called Multi-Armed bandit problem. Imagine standing in front of a row of slot machines. Each machine has a different, completely hidden probability of paying out a reward. If you only have a limited number of tokens, how do you maximize your total winnings?
What we have here is an example of an exploration-exploitation dilemma. Do you keep pulling the lever of the machine that just paid out a few euros (exploiting a known reward), or do you risk your remaining tokens on untried machines in hopes of finding a bigger jackpot (exploring unknown territory)? In Spotify terms, the algorithm tries to squeeze as much attention out of you.
But concretely, how does Spotify mathematically quantify this payout? The system is driven by an AI architecture internally nicknamed BaRT (Bandits for Recommendations as Treatments). In BaRT’s reinforcement learning framework, your phone is the active environment, and your immediate interaction with a recommended track yields a specific numerical reward. This reward is actually binary: If you skip the song within 30 seconds, Spotify registers that as a negative penalty. Otherwise, it receives a positive signal. To maximize its long-term expected payout, BaRT aggregates these quick skips alongside high-value exponential multipliers. A save to your library or adding a track to a personal playlist are the highest-weighted positive signals available. Every tap of your screen instantly recalibrates your personalized taste vector, constantly shifting the probability matrix of what musical lever the bandit will pull next.
The math of choosing your next song is given in this next simplified equation, called epsilon-greedy:
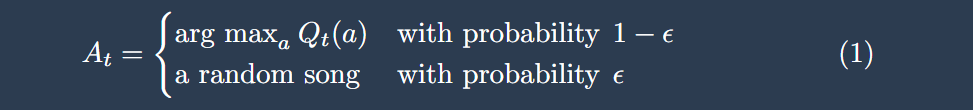
Here, 𝜖 represents a small probability parameter (for example, 𝜖 = 0.05). With a probability of 1-𝜖, the algorithm exploits its current knowledge by selecting the track with the highest historical expected reward. But with a probability of 𝜖, it purposefully explores, tossing a completely random wildcard into your queue to update its estimates of Qt(a) across the entire musical catalog. Without this parameter 𝜖, the algorithm would constantly stay in this exploitation state. Short-term, this would increase listening time, but of course over longer horizons you would get bored hearing the same genre over and over again.
The actual mathematics behind BaRT is substantially more complicated, as for example it also takes into account the current context: How many songs has the user listened to already? What kind of genre were the last 3-5 songs? Even what time of day and day of week is it? Qt(a) becomes Qt(s,a), where s is a vector encoding all of the information above, called the current state. Also, the “random” song isn’t truly random, as that would mean chaos with all the slop that is available on Spotify. It is better seen as guided exploration, which means Spotify won’t stray too far away from your usual music taste.
Everything seems in order for this algorithm to do its job perfectly, but there is one big flaw: How do brand-new tracks with no historical user feedback fight their way into this algorithm? It has zero plays, zero skips, and zero data, meaning the bandit has no incentive to ever pull its lever. To account for this, Spotify stops looking at user behavior and starts analyzing the music itself. When a new track is uploaded, Spotify processes it through two advanced mathematical frameworks: Natural Language Processing (NLP) and Convolutional Neural Networks (CNNs). The NLP models scrape music blogs, reviews and social media to identify which descriptive words are clustering around an artist. In parallel, the audio models (CNN) convert the raw audio file into a spectrogram, which is a visual map of sound, and extract sonic features like tempo, key, and energy level. By merging these linguistic and acoustic profiles, Spotify constructs a proxy vector for the new song before anyone has pressed play. This vector places the track inside a musical neighborhood populated by songs it resembles. When the algorithm then decides to explore, there is a chance that song will be chosen if your profile falls in that category
Ultimately, the music recommended after a day of studying at Zernike is the outcome of a structured optimization process. By modeling user behavior through a contextual multi-armed bandit framework, Spotify systematically evaluates engagement metrics, using skips and full streams to balance immediate satisfaction with user retention.